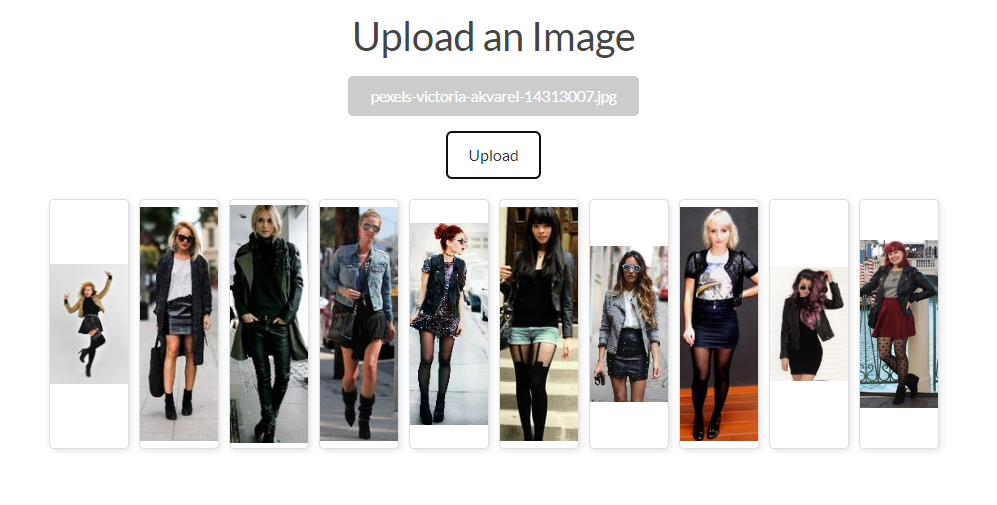
This fashion recommender system is not focused on individual fashion items but on complete outfits. It works by analyzing an input image of a person wearing an outfit and then providing recommendations in the form of images featuring other individuals dressed in coordinated outfits. This approach ensures that the recommendations are not just about single pieces of clothing but are comprehensive ensembles.
Motivation
After recent developments in GenAI, particularly in Vision-Language Models (VLMs), the project I started in December 2022, to develop a fashion recommender, seems already outdated. The original project from 99flairs is outlined here. Driven by curiosity, I decided to revisit the project in a reduced form.
Objective
The objective of this project is to develop a fashion/outfit recommender system that enhances user interaction by providing personalized recommendations. The focus is on achieving style coherence, ensuring the system accurately understands and reflects the user’s preferred fashion styles, and maintaining rich diversity, offering a broad range of clothing items within the recommendations. The aim is not to develop a complete recommender system, as that would require extensive input beyond the scope of this showcase. Instead, the project concentrates on the most challenging aspect that current fashion recommenders struggle with: balancing style coherence with a diverse selection of fashion items.
Approach
It is worth mentioning that the question of how a machine can learn a fashion style has been addressed before by Wei-Lin Hsiao and Kristen Grauman in their excellent research paper: Learning the Latent “Look”: Unsupervised Discovery of a Style-Coherent Embedding from Fashion Images. The main problem is the subjective nature of style and the great obstacle of creating a labeled data set. Then, pre-trained LLMs and VLMs were not as advanced and available as they are today. Currently, I have the luxury of easily implementing a VLM that has been trained on millions of images within hours, and that is what I have done here.
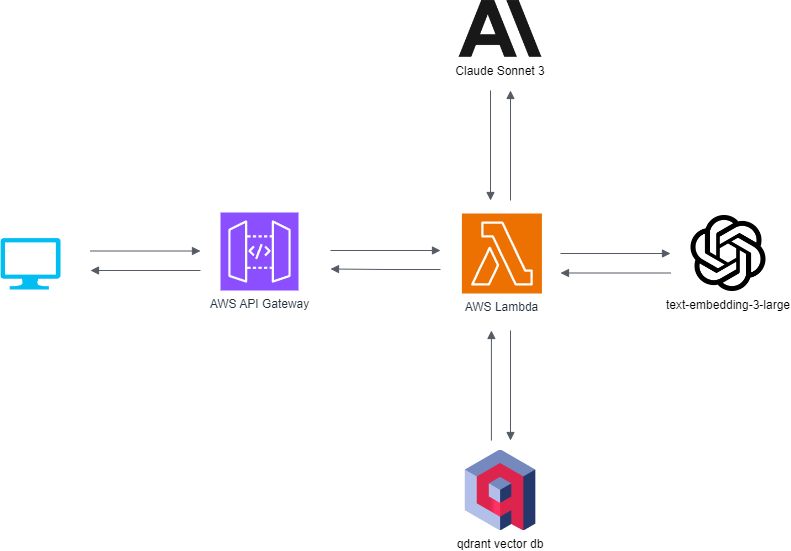
The system, hosted on AWS, begins by using a Lambda function to resize the input image. This image, along with a well-engineered prompt, is then sent to Anthropic’s Claude Sonnet 3 model. The model generates a list of fashion-related vocabulary describing the style of the outfit. This list is then sent to OpenAI’s text-embedding-ada-002 model, which returns a vector representation. Approximately 17,000 images (16,500 women, 500 men) have been processed and stored as vectors in Qdrant’s vector database. For fashion recommendations, the system uses these vectors for similarity searches within Qdrant, rather than storing new vectors. For completeness, I should add that the images are stored on AWS S3, and newly uploaded images are not stored. The dataset I am working with is available here. I have built an interface. You can try out the Generative AI Fashion Recommender here.